Migración de SQL a NoSQL-MONGODB
Intro
Desde hace ya 50 años aproximadamente se han venido usando las bases de datos relacionales basadas en SQL (Structured Query Language), las cuales permiten organizar datos en tablas relacionadas entre sí mediante claves primarias y foráneas, lo cual permite una gestión más eficiente y estructurada de la información.
Sin embargo, con el surgimiento de Internet 2.0 a principios del siglo XXI (donde todos somos generadores y consumidores de contenido), las empresas de Internet comenzaron a enfrentar desafíos con las bases de datos relacionales tradicionales debido a la escala masiva y la naturaleza no estructurada de los datos generados por usuarios de todos el mundo.
A partir de alrededor de 2009, las bases de datos NoSQL (Not Only Structured Query Language) han ido ganando terreno especialmente en aplicaciones web y móviles, así como en escenarios donde la escalabilidad y flexibilidad son prioritarias.
Las bases de datos NoSQL se pueden categorizar en cuatro grupos:
-
Basada en documentos: Almacenan datos en formato de documentos, como JSON o XML, donde cada documento puede contener una estructura flexible y diferente. Ejemplos: MongoDB y Couchbase.
-
Orientadas a columnas: Almacenan datos en columnas en lugar de filas, lo que permite una recuperación rápida y eficiente de datos específicos. Ejemplos: Apache Cassandra y HBase.
-
Clave-valor: Almacenan datos como pares de clave-valor simples, lo que las hace ideales para aplicaciones que requieren una alta velocidad de lectura y escritura. Ejemplos: Redis y Amazon DynamoDB.
-
Grafos: Modelan datos como grafos, que consisten en nodos y relaciones entre ellos, lo que facilita la representación y consulta de relaciones complejas. Ejemplos: Neo4j y Amazon Neptune.
Cada tipo de base de datos NoSQL está optimizado para diferentes casos de uso y requisitos de escalabilidad, consistencia y disponibilidad.
En este artículo/tutorial se va a explicar cómo realizar una migración de una base de datos SQL a NoSQL de tipo Documental (MongoDB). Para realizar esta migración existen múltiples herramientas especializadas donde el proceso es prácticamente automático. Sin embargo, como este blog tiene una orientación didáctica, se utilizarán herramientas más básicas como Google Colab para realizar un preprocesamiento de los datos en lenguaje Python con el fin de transformar las tablas SQL a colecciones de documentos NoSQL de Mongo. A continuación, se ingresarán las colecciones a MongoDB a través del Power Shell de MongoDB, Mongosh.
1. Análisis del diagrama Entidad-Relación de la base de datos
Cuando se trata de migrar datos de una base de datos SQL a NoSQL, primeramente se debe analizar las relaciones entre las tablas dentro de la base de datos. No es posible realizar la migración correctamente sin este trabajo previo debido a que las estructuras son completamente diferentes:
- SQL: su estructura se basa en la relación de claves primarias y foráneas. Según las formas normales, las tablas no deben contener atributos concatenados y no dependientes de otras claves, atributos, o conjunto de atributos que no sean la clave primaria de su tabla. Esto resulta en la existencia de múltiples tablas relacionadas entre sí.
- NoSQL: su estructura es similar a la de un diccionario de Python o un JSON. Ya los datos no están interrelacionados en forma de claves, sino que en lugar de tablas se tienen colecciones de documentos, donde un documento se corresponde con un registro en SQL.
No es el fin de este artículo la explicación exhaustiva de las diferencias entre SQL y NoSQL documental, por lo que no se extenderá la explicación en mayor profundidad.
1.1. Carga de la base de datos en Google Colab
La base de datos a usar para este ejercicio se llama love4pets.db. De partida, no se tiene la estructura de relación-entidad de esta base de datos, por lo que de alguna manera se deben obtener estas relaciones.
Para ello, se usará Google Colab, el cual funciona con el lenguaje Python. Se crea un nuevo archivo y se carga la base de datos.
Tras realizar la carga, nos conectamos a una RAM y Disco de Google Colab y ejecutamos el siguiente código:
!pip install sqlalchemy==2.0.2 # instalación de sqlalchemy
!pip install ipython-sql # instalación de ipython-sql
Estas líneas instalarán una serie de paquetes en la sesión actual de Google Colab para la lectura y tratamiento de datos en SQL sin tener que descargar ningún software especializado para ello ni utilizar servidores adicionales. Luego, se carga la base de datos:
%load_ext sql
%sql sqlite:///love4pets.db
Ahora queda cargada en la memoria la base de datos, por lo que ya podemos comenzar a realizar consultas. Como el objetivo es desentrañar la jerarquía de relaciones entre tablas, se usará la siguiente consulta:
%%sql SELECT
name AS nombre_tabla,
sql AS definicion_tabla
FROM
sqlite_master
WHERE
type='table';
Esta consulta da como resultado una visualización de las definiciones de cada una de las tablas. En ellas, se puede observar qué campo ha sido creado como clave primaria y cuáles son claves foráneas de la tabla correspondiente:
* sqlite:///love4pets.db
Done.
nombre_tabla definicion_tabla
cliente CREATE TABLE cliente(
cliente_id INTEGER NOT NULL PRIMARY KEY, -- AUTOINCREMENT
nombre TEXT NOT NULL,
email TEXT UNIQUE,
telefono TEXT NOT NULL,
contacto TEXT ,
telefono_contacto TEXT,
ciudad TEXT NOT NULL
)
mascota CREATE TABLE mascota(
mascota_id INTEGER NOT NULL PRIMARY KEY, -- AUTOINCREMENT
nombre TEXT NOT NULL,
cliente_id INTEGER NOT NULL,
especie TEXT NOT NULL,
raza TEXT NOT NULL,
fecha_nacimiento DATETIME default CURRENT_DATE NOT NULL,
FOREIGN KEY ( cliente_id ) REFERENCES cliente( cliente_id )
)
producto CREATE TABLE producto(
producto_id INTEGER NOT NULL PRIMARY KEY, -- AUTOINCREMENT
nombre TEXT NOT NULL,
descripcion TEXT NOT NULL,
precio INTEGER NOT NULL
)
orden CREATE TABLE orden(
orden_id INTEGER NOT NULL PRIMARY KEY, -- AUTOINCREMENT
cliente_id INTEGER NOT NULL,
fecha DATETIME default CURRENT_DATE NOT NULL,
FOREIGN KEY ( cliente_id ) REFERENCES cliente( cliente_id )
)
detalle_orden CREATE TABLE detalle_orden(
detalle_id INTEGER NOT NULL,
orden_id INTEGER NOT NULL,
producto_id INTEGER NOT NULL,
cantidad INTEGER NOT NULL,
precio INTEGER NOT NULL,
FOREIGN KEY ( producto_id ) REFERENCES producto( producto_id ),
PRIMARY KEY ( detalle_id, orden_id )
)
proveedor CREATE TABLE proveedor(
proveedor_id INTEGER NOT NULL PRIMARY KEY, -- AUTOINCREMENT
nombre TEXT NOT NULL,
email TEXT UNIQUE,
telefono TEXT NOT NULL UNIQUE
)
suministro CREATE TABLE suministro(
proveedor_id INTEGER NOT NULL,
producto_id INTEGER NOT NULL,
cantidad INTEGER NOT NULL,
fecha DATETIME default CURRENT_DATE NOT NULL,
PRIMARY KEY (proveedor_id, producto_id)
)
1.2. Representación visual e interpretación del diagrama entidad-relación
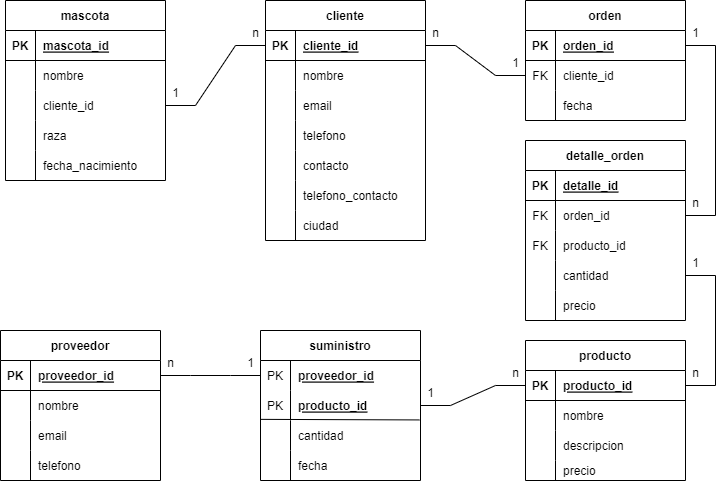
Como se puede observar, se ha representado el modelo de entidad-relación donde se define cada tabla con la entidad que representa, sus atributos y cuales de estos son los primary keys y foreign keys.
Además, se observa la cardinalidad de cada relación, en donde por simplicidad, se ha escogido un modelo donde solo existen relaciones uno a muchos (1:n).
A continuación, se analiza cada relación:
-
Cliente-Mascota: Cada cliente puede tener una o muchas mascotas y cada mascota pertenece a un único cliente.
-
Cliente-orden: Cada cliente puede tener una o muchas órdenes y cada orden tendrá a un único cliente.
-
orden-detalle_orden: Cada orden puede tener uno o muchos detalles de orden (un mismo pedido con varios productos) y cada detalle_orden corresponderá a una única orden.
-
producto-detalle_orden: Cada producto puede aparecer en uno o varios detalles de órdenes y cada detalle de orden debe tener un único producto.
-
producto-suministro: Cada producto puede aparecer en uno o varios suministros y cada suministro debe tener un único producto.
-
proveedor-suministro: Cada proveedor puede aparecer en uno o varios suministros y cada suministro debe tener un único proveedor.
Nótese que la tabla detalle_orden surge de una relación n:m entre las entidades orden y producto. Con la existencia de esta tabla se elimina este tipo de relación y se garantiza la unicidad de los datos.
Además, se habrá observado que la entidad suministro tiene dos atributos que son PK. Ojo, esto no significa que la tabla tenga dos PK (esto sería incorrecto), significa que el PK se compone de dos atributos. Es decir, el PK se puede entender como la composición de dos atributos para garantizar la unicidad del registro.
Estructura objetivo: colecciones de documentos
2. Creación de colecciones de documentos a partir de la base de datos relacional
Tras analizar el esquema de entidad-relación, se procede a elaborar las colecciones (tablas) necesarias así como los documentos (registros) contenidos en las colecciones. Para ello, se utilizará el objeto Diccionario de Python. De esta forma, se creará una estructura similar a un JSON y, por lo tanto, compatible con el formato de las colecciones basadas en la estructura “Clave-valor”.
La estrategia que se va a seguir para la migración de SQL a NoSQL se basa en la incrustración de documentos.
Debido a que en NoSQL se pierden las relaciones (relaciones de tablas a través de claves primarias y foráneas), las entidades que tengan una relación M:1 deberán de ir contenidas en documentos de las colecciones principales de cardinalidad 1. Es decir, en lenguaje NoSQL, se crearán tantas colecciones como entidades no dependientes de otras entidades haya en la base de datos de cardinalidad 1:M. El resto de tablas cuya cardinalidad sea M:1, deberán incluirse como un arreglo de documentos dentro del otro documento asociado.
Estas serán las colecciones de documentos principales. El resto de tablas irán incluidas como arreglos de documentos dentro de uno o más de estas colecciones principales. La información de estos arreglos de documentos, debido a que se pierden las relaciones, puede estar duplicada en diferentes colecciones principales.
Las tablas que tienen relación 1:M y que serán colecciones principales son:
- Cliente - orden
- Cliente - mascota
- Producto - detalle_orden
- Producto - suministro
- Proveedor - suministro
2.1. Consulta de tablas y creación de lista de diccionarios
Para comenzar, se van a formatear las tablas de la base de datos en forma de lista de diccionarios. En lenguaje NoSQL, se crearán colecciones de documentos.
Se crea una lista por cada tabla, suponiendo como punto de partida que cada tabla será una colección en sí misma.
En primer lugar, se deberá de crear una colección vacía por cada entidad:
cliente = []
mascota = []
producto = []
orden = []
detalle_orden = []
proveedor = []
suministro = []
Con el fin de poder manipular las tablas en bucle, se incluyen todas en una lista de tuplas, conteniendo estas tuplas la colección en sí (objeto lista) y el nombre de la lista en string, que coincidirá con el nombre de la tabla de la base de datos.
lst_colecciones = [
(cliente, 'cliente'),
(mascota, 'mascota'),
(producto, 'producto'),
(orden, 'orden'),
(detalle_orden, 'detalle_orden'),
(proveedor, 'proveedor'),
(suministro, 'suministro'),
]
Se cumplimenta cada colección con los registros de su tabla, donde cada registro se convertirá en un documento con pares clave-valor.
Para realizar el proceso de forma iterativa, se creará una función que pueda ser llamada y cuyo argumento sea la tupla (colección, nombre de la colección) que contendrá la colección ya formateada en formato JSON, apropiado para bases de datos NoSQL.
def format_NoSQL(coleccion):
#Se desempaqueta la tupla de la coleccion
obj_coleccion, nombre = coleccion
#Se almacena la consulta en una variable
tabla = %sql SELECT * FROM {nombre}
#Se convierte en diccionario para iterar con mayor control
tabla = tabla.dict()
'''Se itera sobre cada registro para almacenar en un
diccionario en forma de clave-valor el nombre del campo
y el valor del par campo-registro. Luego, el diccionario
creado se almacena en la lista correspondiente, creando
así una coleccion de documentos, donde cada documento
corresponderá a un registro.'''
#Se obtiene el numero de registros
for valor in tabla.values():
n_registros = len(valor)
#Solo hace falta iterar una vez, así que salimos del bucle
break
for i in range(n_registros):
'''Se crea el diccionario donde se va a almacenar cada documento
con la estructura compatible con NoSQL'''
dic_colec = {}
'''Se itera entre claves y valores del diccionario, que son los
campos y registros de la tabla'''
for campo, registro in tabla.items():
dic_colec[campo] = registro[i]
#Se añade el documento a la coleccion
obj_coleccion.append(dic_colec)
return dic_colec
A continuación, se itera sobre la lista de colecciones para enviar las distintas colecciones a la función format_NoSQL.
for coleccion in lst_colecciones:
format_NoSQL(coleccion)
Se verifica el resultando observando dos tablas cualesquiera.
cliente[:3] #Se muestran solo los tres primeros resultados de la lista de cliente
Output:
[{'cliente_id': 1,
'nombre': 'Mario Flores Gallardo',
'email': 'marioflores@gmail.com',
'telefono': '036-15-36',
'contacto': 'Aintzane Alvarez Iglesias',
'telefono_contacto': '210-35-57',
'ciudad': 'Madrid'},
{'cliente_id': 2,
'nombre': 'Arnau Medina Garcia',
'email': 'arnaumedina@gmail.com',
'telefono': '094-10-88',
'contacto': '',
'telefono_contacto': '',
'ciudad': 'Madrid'},
{'cliente_id': 3,
'nombre': 'Ivan Medina Rubio',
'email': 'ivanmedina@gmail.com',
'telefono': '083-08-72',
'contacto': 'Javier Domenech',
'telefono_contacto': '488-48-46',
'ciudad': 'Toledo'}]
producto[:3] #Se muestran solo los tres primeros resultados de la lista de producto
Output:
[{'producto_id': 1,
'nombre': 'Champu Mimadito',
'descripcion': 'Champu neutro para mascotas',
'precio': 7},
{'producto_id': 2,
'nombre': 'Vitaminas',
'descripcion': 'Complemento vitaminico',
'precio': 5},
{'producto_id': 3,
'nombre': 'Antipulgas',
'descripcion': 'Liquido antipulgas',
'precio': 3}]
2.2. Incrustación de documentos
Una vez tengamos cada colección en el formato deseado, se procede a relacionar unas colecciones con otras.
Cada colección corresponde a una de las tablas de la base de datos original y, cada tabla, se relaciona con, al menos, una tabla más. Por lo tanto, se van a buscar los valores relacionados dentro de cada colección con la otra colección o colecciones con las que se relaciona.
La manera de operar es similar a la de un JOIN de SQL, donde se buscarán las coincidencias entre, por ejemplo, cliente_id de la tabla cliente (ya transformado en una colección) y la clave foránea cliente_id de la tabla mascotas (también ya en formato colección).
En caso de coincidencia, se añadirá al documento correspondiente una nueva clave con el nombre de la colección, por ejemplo “mascota”, y de valor un arreglo de documentos. Este arreglo contendrá tantos documentos como coincidencias haya para el mismo registro.
El valor será un arreglo y no directamente un documento porque cada cliente puede tener varias mascotas y, por lo tanto, tener varios registros a su nombre.
Como cada mascota tendrá un dueño como mínimo, no quedará ningún registro de mascota fuera y no habrá pérdida de información.
Esta lógica se aplica para todas las tablas que tienen relación 1:M-M:1.
Como esta operación se va a realizar más de una vez, se escribe una función genérica para no replicar código.
'''La funcion contiene tres argumentos, en orden:
coleccion con cardinalidad 1
id de clave de relacion
coleccion con cardinalidad M
'''
def unifColecTipo1(coleccion_1, id_1, coleccion_M):
obj_coleccion_M = coleccion_M[0] #Selecciono el objeto lista/colec de la tupla
nombre_coleccion_M = coleccion_M[1] #Selecciono el str nombre de la tupla
obj_coleccion_1 = coleccion_1[0]
for documento_M in obj_coleccion_M: #Se itera en cada documento de card. M
for documento_1 in obj_coleccion_1: #Se itera en cada documento de card. 1
'''Se comprueba si coinciden los id de claves primarias y foraneas. Si
esto sucede, significa que se ha encontrado el unico registro de
cardinalidad 1 para el que el registro de cardinalidad M existe.
Ej: se ha encontrado al cliente dueño de una mascota'''
if documento_M[id_1] == documento_1[id_1]:
#Se comprueba si existe ya una clave con el nombre de la coleccion M
if nombre_coleccion_M not in documento_1:
#Se crea una lista vacia que representa un arreglo de documentos
documento_1[nombre_coleccion_M] = []
documento_1[nombre_coleccion_M].append(documento_M)
break
Una vez escrita la función, se le llama pasándole los argumentos necesarios. Se probará en primer lugar con la relación entre cliente y mascota.
unifColecTipo1((cliente, "cliente"), "cliente_id", (mascota, "mascota"))
Se verifica el resultado:
cliente[:3]
Output:
[{'cliente_id': 1,
'nombre': 'Mario Flores Gallardo',
'email': 'marioflores@gmail.com',
'telefono': '036-15-36',
'contacto': 'Aintzane Alvarez Iglesias',
'telefono_contacto': '210-35-57',
'ciudad': 'Madrid'},
{'cliente_id': 2,
'nombre': 'Arnau Medina Garcia',
'email': 'arnaumedina@gmail.com',
'telefono': '094-10-88',
'contacto': '',
'telefono_contacto': '',
'ciudad': 'Madrid',
'mascota': [{'mascota_id': 1,
'nombre': 'Luna',
'cliente_id': 2,
'especie': 'gato',
'raza': 'mestizo',
'fecha_nacimiento': '2009-01-01 00:00:000'}]},
{'cliente_id': 3,
'nombre': 'Ivan Medina Rubio',
'email': 'ivanmedina@gmail.com',
'telefono': '083-08-72',
'contacto': 'Javier Domenech',
'telefono_contacto': '488-48-46',
'ciudad': 'Toledo',
'mascota': [{'mascota_id': 2,
'nombre': 'Sole',
'cliente_id': 3,
'especie': 'gato',
'raza': 'mestizo',
'fecha_nacimiento': '2010-02-01 00:00:000'},
{'mascota_id': 3,
'nombre': 'Mida',
'cliente_id': 3,
'especie': 'perro',
'raza': 'Caint terrier',
'fecha_nacimiento': '2007-02-03 00:00:000'}]}]
Se puede observar que se ha conseguido el efecto deseado.
Se procede de forma similar con el resto de documentos que tienen relaciones 1:M teniendo en cuenta el orden en que se realiza la operación. Este orden es importante ya que si hay una colección principal que contenga a un arreglo de documentos que, a su vez, contenga arreglos de documentos, la colección principal deberá contener toda esta anidación. Por lo tanto, primero se realizará la incrustación de los niveles más profundos y se irá ejecutando hacia el nivel superior.
Por ejemplo, detalle_orden se incrustará dentro de orden. Una vez orden contenga a detalle_orden, ésta se incrustará dentro de cliente. Por lo tanto, finalmente cliente contendrá a orden y detalle_orden con dos niveles de profundidad. Además, cliente contendrá a mascota, ya incrustada anteriormente.
Por lo tanto, cliente será una colección de documentos con hasta dos niveles de profundidad de documentos incrustados.
#Creacion de coleccion principal "cliente" (ojo, ya se incrustó la tabla "mascota")
unifColecTipo1((orden, "orden"), "orden_id", (detalle_orden, "detalle_orden"))
unifColecTipo1((cliente, "cliente"), "cliente_id", (orden, "orden"))
#Creacion de coleccion principal "producto"
unifColecTipo1((producto, "producto"), "producto_id", (detalle_orden, "detalle_orden"))
unifColecTipo1((producto, "producto"), "producto_id", (suministro, "suministro"))
#Creación de coleccion principal "proveedor"
unifColecTipo1((proveedor, "proveedor"), "proveedor_id", (suministro, "suministro"))
En este punto, se tienen tres colecciones:
- Cliente
- Producto
- Proveedor
2.3. Eliminación de redundancias
Para cada una de estas colecciones principales se ha incluido los documentos asociados conteniendo estos todos los campos de las tablas. Es decir, las claves primarias y secundarias, aunque ya no ejercen de conexiones siguen estando ahí.
Esto es información redundante, ya que si existe, por ejemplo, un array de documentos de orden dentro de un documento de la colección clientes, significa que no puede ser una orden de otro cliente que no sea el cliente del documento en el que está contenido.
Por lo tanto, para cada colección principal se ha de proceder a eliminar estas claves primarias y foráneas de los documentos.
Sin embargo, hay excepciones. Si una colección o array de documentos aparece en más de una colección principal, la eliminación de sus claves relacionales implicaría la pérdida de cierta información. Por ejemplo, detalle_orden está contenida dentro del array de documentos de orden que a su vez está contenido en la colección clientes, pero además, detalle_orden está contenido en otra colección, producto. Si se quisiera relacionar un producto con los clientes y se elimina esta relación de claves, se perdería esta información.
Por lo tanto, solo se van a eliminar las claves primarias de las colecciones principales, pero se mantendrán las claves de las subcolecciones, es decir, de los arrays de documentos.
Para poder llevar a cabo lo explicado técnicamente, se va a crear una función cuyos argumentos serán la colección y el id que se quiere eliminar. Esta será un tipo de función muy especial, llamada recursiva, pues se llama a sí misma cuantas veces sean necesarias. Esto sirve para poder navegar hasta el nivel de profundidad necesario sin necesidad de configurar la función para un nivel específico, pues diferentes colecciones tienen diferentes niveles de profundidad.
Por cada documento que encuentra, verifica si el id pasado como argumento se encuentra entre las claves del mismo y, si es así, lo elimina.
def eliminar_campo_id(coleccion, id):
for documento in coleccion:
if id in documento:
del documento[id]
for clave, valor in documento.items():
if isinstance(valor, list):
eliminar_campo_id(valor, id)
Visualización de la colección cliente antes de llamar a la función:
cliente[:1]
Output:
[{'cliente_id': 1,
'nombre': 'Mario Flores Gallardo',
'email': 'marioflores@gmail.com',
'telefono': '036-15-36',
'contacto': 'Aintzane Alvarez Iglesias',
'telefono_contacto': '210-35-57',
'ciudad': 'Madrid',
'orden': [{'orden_id': 2,
'cliente_id': 1,
'fecha': '2018-02-01 00:00:000',
'detalle_orden': [{'detalle_id': 4,
'orden_id': 2,
'producto_id': 3,
'cantidad': 3,
'precio': 3},
{'detalle_id': 5,
'orden_id': 2,
'producto_id': 5,
'cantidad': 1,
'precio': 13}]}]}]
Se llama a la función eliminar_campo_id():
eliminar_campo_id(cliente, "cliente_id")
Visualización de la colección cliente después de llamar a la función:
cliente[:1]
Output:
[{'nombre': 'Mario Flores Gallardo',
'email': 'marioflores@gmail.com',
'telefono': '036-15-36',
'contacto': 'Aintzane Alvarez Iglesias',
'telefono_contacto': '210-35-57',
'ciudad': 'Madrid',
'orden': [{'orden_id': 2,
'fecha': '2018-02-01 00:00:000',
'detalle_orden': [{'detalle_id': 4,
'orden_id': 2,
'producto_id': 3,
'cantidad': 3,
'precio': 3},
{'detalle_id': 5,
'orden_id': 2,
'producto_id': 5,
'cantidad': 1,
'precio': 13}]}]}]
Como se puede observar, se han eliminado todos los cliente_id de todos los niveles de la colección. Por lo tanto, se opera de la misma manera con el resto de colecciones principales.
eliminar_campo_id(producto, "producto_id")
eliminar_campo_id(proveedor, "proveedor_id")
2.4. Exportación a JSON
Por último, todas las colecciones generadas a través de listas y diccionarios en Python se exportarán como archivos JSON para, posteriormente, importarlos desde MongoDB y así crear las colecciones.
Se usará el módulo “json”, el cual está integrado dentro de las bibliotecas por defecto de Python.
import json
lst_colecciones_ppales = [(cliente, "cliente"),
(producto, "producto"),
(proveedor, "proveedor"),
]
for coleccion, nombre in lst_colecciones_ppales:
# Ruta para guardar los archivo JSON
ruta_colec_json = '/content/' + nombre + '.json'
# Escribir la lista de diccionarios en el archivo JSON
with open(ruta_colec_json, 'w') as archivo_json:
json.dump(coleccion, archivo_json)
Tan solo queda descargar los documentos exportados a la sesión actual de Google Colab en local.
3. Creación de la base de datos NoSQL en MongoDB
Para poder operar en MongoDB se necesita completar una serie de pasos previos, como el registro en MongoDB Atlas, creación de un cluster, etc… Sin embargo, debido a la existencia de manuales exclusivos para la realización de este proceso, no se explicará en este documento ya que no es parte del objetivo del mismo.
Por lo tanto, se parte de que ya se tiene un usuario creado en Atlas y un cluster operativo.
3.1. Entorno de trabajo: Shell de Mongo (Mongosh)
Aunque hay distintas formas de poder conectarse al cluster de MongoDB se va a utilizar el Shell de Mongo (mongosh).
La elección de esta herramienta se debe a la posibilidad de usar directamente el lenguaje MQL (MongoDB Query Language). El uso de otros softwares como la extensión de MongoDB for VS Code conlleva el uso de un lenguaje distinto, ya que MQL no es compatible completamente con todas las aplicaciones.
Como el desarrollo de este documento tiene fines didácticos, se utilizará por tanto la terminal Shell de Mongo.
Así pues, se seguirán las instrucciones adecuadas para la instalación de Mongosh y, una vez abierta, se procede a la conexión con el cluster. Esta conexión se produce mediante una cadena de texto y contraseña generada desde la web de MongoDB e insertada desde nuestra terminal.

Desde este momento, ya se puede realizar las consultas MQL en el cluster.
3.2. Creación de la base de datos e ingreso de las colecciones
Se crea la base de datos directamente con la sentencia que declara que se quiere usar dicha base de datos.
Atlas atlas-59qnuo-shard-0 [primary] admin> use love4pets
Output:
switched to db love4pets
Una vez creada, se crean las diferentes colecciones, las cuales estarán aún vacías.
Atlas atlas-59qnuo-shard-0 [primary] love4pets> db.createCollection("cliente")
Output:
{ ok: 1 }
Una vez se tienen las colecciones creadas, se cargan los JSON a cada colección.
Por cada archivo JSON que se creó anteriormente, se debe abrir, seleccionar y copiar la colección y, por último, pegar esta colección dentro de la función insertMany() de mongosh.
A continuación se mostrará todo el proceso con el ejemplo de la colección cliente.
Primero, se copia la colección del JSON abierto (se puede usar un editor de código como VS Code o simplemente en texto plano con el bloc de notas).

A continuación, se insertan los datos del JSON en la colección cliente.
db.cliente.insertMany([{"nombre": "Mario Flores Gallardo", "email": "marioflores@gmail.com",
"telefono": "036-15-36", "contacto": "Aintzane Alvarez Iglesias", "telefono_contacto":
"210-35-57", "ciudad": "Madrid", "orden": [{"orden_id": 2, "fecha":
"2018-02-01 00:00:000", "detalle_orden": [{"detalle_id": 4, "orden_id": 2,
"cantidad": 3, "precio": 3}, {"detalle_id": 5, "orden_id": 2, "cantidad": 1,
"precio": 13}]}]} ... ])
Output:
{
acknowledged: true,
insertedIds: {
'0': ObjectId("65e4a4b27e11d699784448a5"),
'1': ObjectId("65e4a4b27e11d699784448a6"),
'2': ObjectId("65e4a4b27e11d699784448a7"),
'3': ObjectId("65e4a4b27e11d699784448a8"),
'4': ObjectId("65e4a4b27e11d699784448a9"),
'5': ObjectId("65e4a4b27e11d699784448aa"),
'6': ObjectId("65e4a4b27e11d699784448ab"),
'7': ObjectId("65e4a4b27e11d699784448ac"),
'8': ObjectId("65e4a4b27e11d699784448ad"),
'9': ObjectId("65e4a4b27e11d699784448ae"),
'10': ObjectId("65e4a4b27e11d699784448af"),
'11': ObjectId("65e4a4b27e11d699784448b0"),
'12': ObjectId("65e4a4b27e11d699784448b1"),
'13': ObjectId("65e4a4b27e11d699784448b2"),
'14': ObjectId("65e4a4b27e11d699784448b3")
}
}
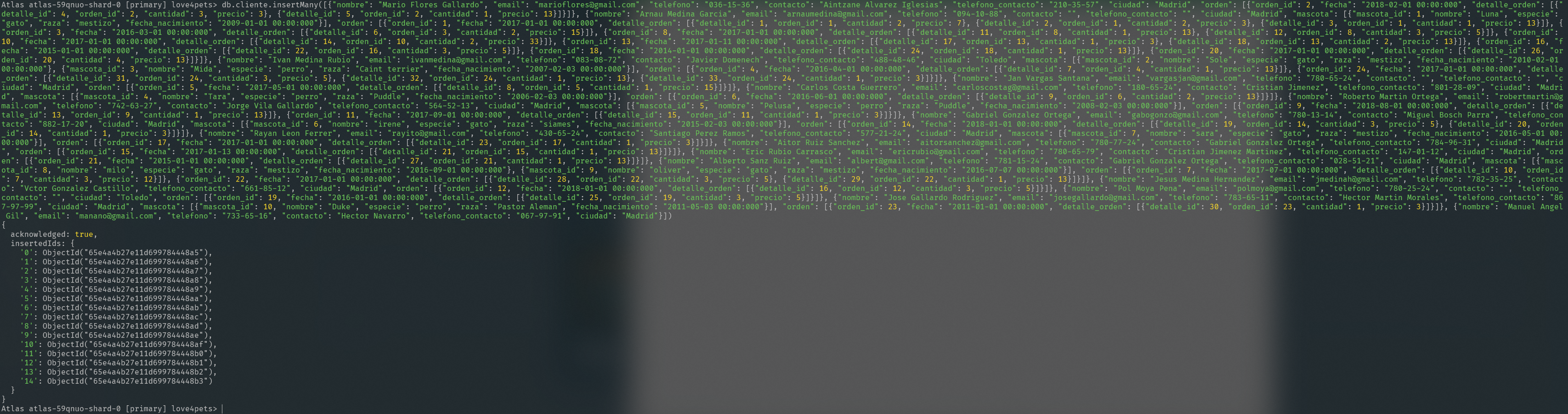
Tras este proceso, se habrá insertado exitosamente la colección cliente en la base de datos love4pets.
Para finalizar con la migración, se procede de igual manera con el resto de colecciones almacenadas en los archivos JSON.
3.3. Comprobaciones y consultas
Existen varias formas de comprobar que la base de datos está correctamente creada con sus colecciones insertadas debidamente. Una de ellas es acceder a nuestro perfil en la página oficial de MongoDB y acceder a nuestras bases de datos.
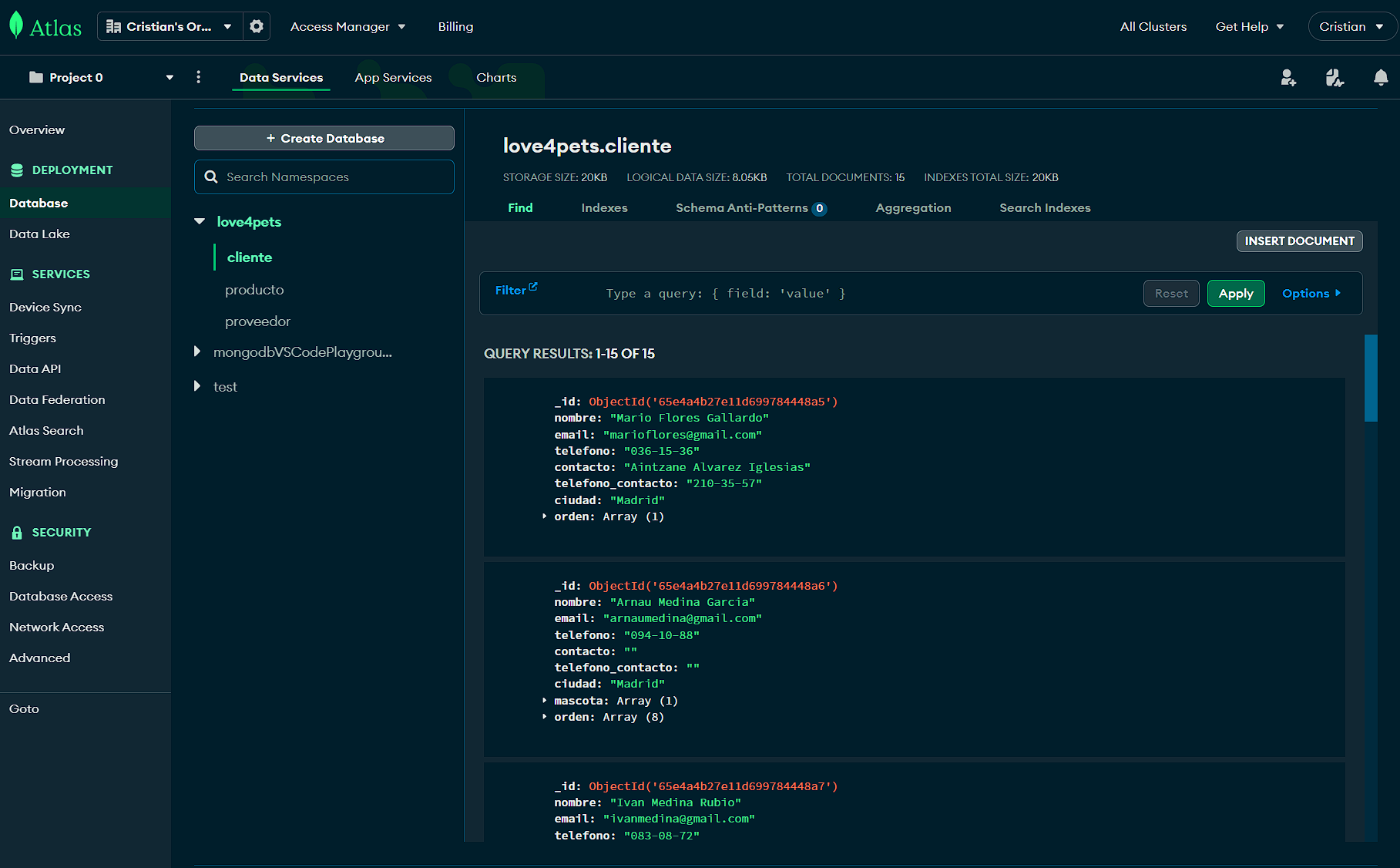
Como se puede observar en la figura anterior, aparece dentro del apartado Deployment/Database la base de datos love4pets así como las cuatro colecciones creadas. Además, se verifica visualmente que dentro de dicha colección existen los distintos documentos con los datos correspondientes más un identificador. Este identificador es un objeto creado automáticamente por MongoDB y apunta al objeto documento, haciéndolo único para su referenciación.
Otra forma de verificar la correcta migración es la consulta a través del Power Shell de MongoDB. Por ejemplo, se procede a buscar el documento del proveedor maxipet:
db.proveedor.find({"nombre":"maxipet"})
Output:
[
{
_id: ObjectId("65e4a5767e11d699784448c4"),
nombre: 'maxipet',
email: 'maxipet@gmail.com',
telefono: '8650001508',
suministro: [
{ cantidad: 5, fecha: '2015-01-01 00:00:000' },
{ cantidad: 5, fecha: '2015-01-01 00:00:000' }
]
}
]
La búsqueda ha sido exitosa. Probemos, además, con la búsqueda de aquellos productos que cuesten más de seis unidades monetarias.
db.producto.find({"precio": {$gt: 6}})
Output:
[
{
_id: ObjectId("65e4a52b7e11d699784448bb"),
nombre: 'Champu Mimadito',
descripcion: 'Champu neutro para mascotas',
precio: 7,
detalle_orden: [ { detalle_id: 1, orden_id: 1, cantidad: 2, precio: 7 } ],
suministro: [ { cantidad: 30, fecha: '2015-01-01 00:00:000' } ]
},
{
_id: ObjectId("65e4a52b7e11d699784448be"),
nombre: 'Perrarina',
descripcion: 'Huesos',
precio: 12,
detalle_orden: [ { detalle_id: 10, orden_id: 7, cantidad: 3, precio: 12 } ],
suministro: [ { cantidad: 5, fecha: '2015-01-01 00:00:000' } ]
},
{
_id: ObjectId("65e4a52b7e11d699784448bf"),
nombre: 'Gatarina',
descripcion: 'Catspettito',
precio: 13,
detalle_orden: [
{ detalle_id: 3, orden_id: 1, cantidad: 1, precio: 13 },
{ detalle_id: 5, orden_id: 2, cantidad: 1, precio: 13 },
{ detalle_id: 7, orden_id: 4, cantidad: 1, precio: 13 },
{ detalle_id: 9, orden_id: 6, cantidad: 2, precio: 13 },
{ detalle_id: 11, orden_id: 8, cantidad: 1, precio: 13 },
{ detalle_id: 13, orden_id: 9, cantidad: 1, precio: 13 },
{ detalle_id: 18, orden_id: 13, cantidad: 2, precio: 13 },
{ detalle_id: 21, orden_id: 15, cantidad: 1, precio: 13 },
{ detalle_id: 24, orden_id: 18, cantidad: 1, precio: 13 },
{ detalle_id: 26, orden_id: 20, cantidad: 4, precio: 13 },
{ detalle_id: 27, orden_id: 21, cantidad: 1, precio: 13 },
{ detalle_id: 29, orden_id: 22, cantidad: 1, precio: 13 },
{ detalle_id: 32, orden_id: 24, cantidad: 1, precio: 13 }
],
suministro: [ { cantidad: 5, fecha: '2015-01-01 00:00:000' } ]
},
{
_id: ObjectId("65e4a52b7e11d699784448c2"),
nombre: 'Consulta',
descripcion: 'Consulta veterinaria',
precio: 15,
detalle_orden: [
{ detalle_id: 6, orden_id: 3, cantidad: 2, precio: 15 },
{ detalle_id: 8, orden_id: 5, cantidad: 1, precio: 15 }
]
}
]
Cambiemos ahora el teléfono de un cliente, simulando que ha cambiado de número y queremos actualizar la base de datos.
db.cliente.update({"nombre": "Roberto Martin Ortega"}, {$set: {"telefono": "565-38-78"}})
Output:
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}
Aprovechando que se ha actualizado el teléfono de Roberto, vamos a comprobar que ha cambiado y, además, veamos los datos de su mascota. Como solo queremos ver la información del teléfono y de la mascota, se añade un segundo parámetro en la función find() que define los campos que queremos que devuelva (además del ObjectId que lo devuelve por defecto a menos que se le indique lo contrario).
db.cliente.find({"nombre":"Roberto Martin Ortega"}, {"telefono":1, "mascota": 1})
Output:
[
{
_id: ObjectId("65e4a4b27e11d699784448aa"),
telefono: '565-38-78',
mascota: [
{
mascota_id: 5,
nombre: 'Pelusa',
especie: 'perro',
raza: 'Puddle',
fecha_nacimiento: '2008-02-03 00:00:000'
}
]
}
]
Por tanto, después de hacer las comprobaciones se puede asegurar que la base de datos ha sido migrada exitosamente de SQL a NoSQL en un cluster en el Cloud de MongoDB.